


Na última semana, uma notícia trouxe o que possivelmente é o panorama mais claro do que podemos esperar da resposta da Apple a ferramentas como o ChatGPT e o Microsoft Copilot.
Sem alarde, um grupo de pesquisadores de inteligência artificial e machine learning (aprendizado de máquina, ou ML) da empresa publicou um estudo chamado “LLM1Large language models, ou grandes modelos de linguagem. in a flash: Efficient Large Language Model Inference with Limited Memory” — ou, em tradução livre, “LLM em um flash2Trocadilho com a tecnologia de memória NAND flash, responsável pela capacidade de armazenamento dos iPhones.: Inferência Eficiente Para Grande Modelo de Linguagem com Memória Limitada”.
Esse estudo traz uma possível solução bastante criativa para um dos principais dilemas que a Apple vem enfrentando quando o assunto é IA generativa: o equilíbrio entre privacidade e utilidade.

O que acontece é o seguinte: nos últimos anos, a Apple passou a fazer diversas análises diretamente no aparelho, reduzindo o volume de dados que precisam deixar o dispositivo. Um benefício colateral disso foi um ganho em desempenho, em comparação à necessidade de enviar a informação para o servidor, esperar ela ser processada lá, e então baixar o resultado. Para IAs generativas, a Apple pretende fazer a mesma coisa.
O problema é que os LLMs parrudos são tão grandes que não cabem nos dispositivos da maioria das pessoas. Por isso, eles só podem ser acessados via internet. Na contramão disso, os modelos feitos para caberem nos dispositivos das pessoas tendem a ser menos potentes, pela necessidade de serem menores.
No caso do ChatGPT, por exemplo, o modelo GPT-3 tinha 175 bilhões de parâmetros3Quantidade de “pesos” que os modelos utilizam para fazer previsões ou para gerar um texto.. Para o GPT-4, a OpenAI não divulgou o número de parâmetros, mas o hacker George Hotz afirmou no Lex Fridman Podcast que esse número é de aproximadamente 1,76 trilhão4Segundo Hotz, o GPT-4 é um conjunto de 8 modelos com 220 bilhões de parâmetros cada.. Outras estimativas incluem o fato de ele pesar 500GB e precisar de outros 300GB de VRAM5Video Random Access Memory, ou memória de acesso aleatório a vídeo. para funcionar.
Obviamente, quase ninguém poderia rodar isso localmente. E, para rodá-lo na internet, é necessária uma estrutura gigantesca para acomodar a quantidade de pessoas fazendo consultas simultâneas, além para analisar e oferecer as respostas com a rapidez com a qual nós já nos acostumamos.
Cada vez que nós enviamos um prompt6Termo para pedido, comando ou solicitação enviado a uma IA generativa. para o ChatGPT, os neurônios do sistema basicamente desmembram e analisam o conteúdo e o contexto desse prompt, aplicam seus pesos e vieses, e organizam esses dados para facilitar a consulta e comparação dos 1,76 trilhão de parâmetros distribuídos em mais de 120 camadas para gerar o resultado.
Quando fazemos um segundo prompt, esse processo acontece novamente, incluindo um novo envio e uma nova análise tanto do primeiro prompt quanto da primeira resposta. Este é um processo chamado autorregressivo. Dependendo da tarefa, essas etapas podem ser divididas e acontecer de forma paralela, agilizando todo o processo. Sorte da OpenAI de poder contar com toda a estrutura do Microsoft Azure à sua disposição, não?

A nova corrida dos modelos locais
Para rodar um modelo localmente, é necessário que ele seja bem menor e exija bem menos recursos computacionais do que os modelos que residem na nuvem. Esses são os chamados SMLs7Small language models, ou modelos pequenos de linguagem..
Aqui, o desafio é fazer com que o modelo tenha o menor tamanho possível, sem que ele perca (muito) o desempenho em comparação aos LLMs. É um equilíbrio difícil, que somente nas últimas semanas algumas empresas parecem ter começado a alcançar.
O Google, por exemplo, anunciou recentemente o modelo Gemini Nano para os telefones Pixel 8 Pro. Sua versão mais simples conta com 1,8 bilhão de parâmetros (ou seja, apenas 0,1% do estimado para o GPT-4). Já sua versão mais completa conta com 3,2 bilhões de parâmetros. Ambas, porém, são menos capazes do que a versão Ultra do mesmo modelo, que rodará na nuvem (e que o Google promete que será melhor do que o GPT-4).
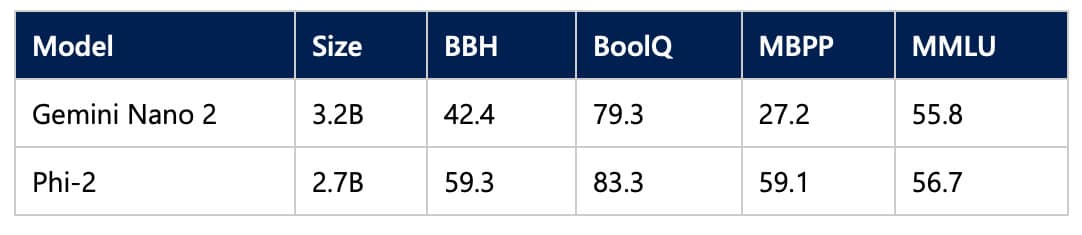
Já a Microsoft lançou há pouco mais de dez dias o SML Phi-2. Com 2,7 bilhões de parâmetros, a empresa diz que ele já ultrapassa o desempenho de modelos 25x maiores do que ele, incluindo o Llama-2 da Meta, que conta com 7 bilhões de parâmetros.
No caso da Apple, se ela não tem uma estrutura do tamanho de um Microsoft Azure ou um Amazon AWS para dar suporte a um modelo gigantesco que rode online, e se ela não se satisfizer com a ideia de lançar um modelo reduzido e com desempenho limitado para rodar localmente nos nossos dispositivos, o que resta?
É aí que entra o estudo recém-anunciado. Nele, os pesquisadores da empresa não apenas mostram criatividade para resolver esse problema, mas apresentam o que pode ser a chave para permitir que algo como uma “Siri GPT” seja verdadeiramente útil, rápida e privada.
O estudo
Para entender o problema que o estudo resolve, precisamos primeiro entender o problema.
O que acontece é o seguinte: atualmente, nossos iPads e iPhones vêm equipados com a memória chamada DRAM8Dynamic random access memory, ou memória dinâmica de acesso aleatório., além do drive tradicional de armazenamento flash. O papel da DRAM é armazenar temporariamente alguns dados e arquivos para oferecer um acesso mais rápido, em comparação ao tempo que levaria para o sistema buscar, identificar, carregar e acessar esses mesmos dados na memória flash9Obviamente a tecnologia é mais complicada do que dá para explicar em um parágrafo, mas o resumo é esse..
A questão é que, enquanto o armazenamento flash dos iPhones atuais, por exemplo, varia entre 128GB e 1TB, a DRAM varia apenas entre 6GB e 8GB. Isso significa que, no caso de um LLM local, a Apple teria que escolher entre carregar apenas um modelo bem pequeno e limitado que pudesse caber na DRAM, ou então armazenar um modelo um pouco maior na memória flash, mas com um desempenho mais lento.
Como os próprios pesquisadores da Apple explicam:
Um modelo com 7 bilhões de parâmetros requer mais de 14GB de memória apenas para carregar os parâmetros […], excedendo a capacidade da maioria dos dispositivos.
Pois bem. No estudo, eles propõem uma solução bastante interessante: eles armazenam o modelo inteiro na memória flash, mas implementam um segundo modelo, chamado modelo de custo de inferência, que identifica e transfere para a DRAM apenas os parâmetros necessários para cumprir o pedido que foi feito pelo usuário.
Para isso, o modelo age em duas etapas: primeiro, ele emprega uma técnica chamada de janela deslizante, que carrega da memória flash para a DRAM apenas os parâmetros dos tokens mais recentes. Isso reduz a quantidade de vezes que o modelo precisa receber, processar e retornar informações, tornando o processo mais eficiente.
Em segundo lugar, o modelo emprega uma técnica chamada agregação de linha-coluna. Basicamente, ele organiza os parâmetros na memória flash em blocos maiores e estrategicamente próximos uns dos outros, tornando a sua leitura mais rápida e eficiente. Desta forma, aqui também perde-se menos tempo buscando, identificando e transferindo dados para dentro e para fora da memória flash.
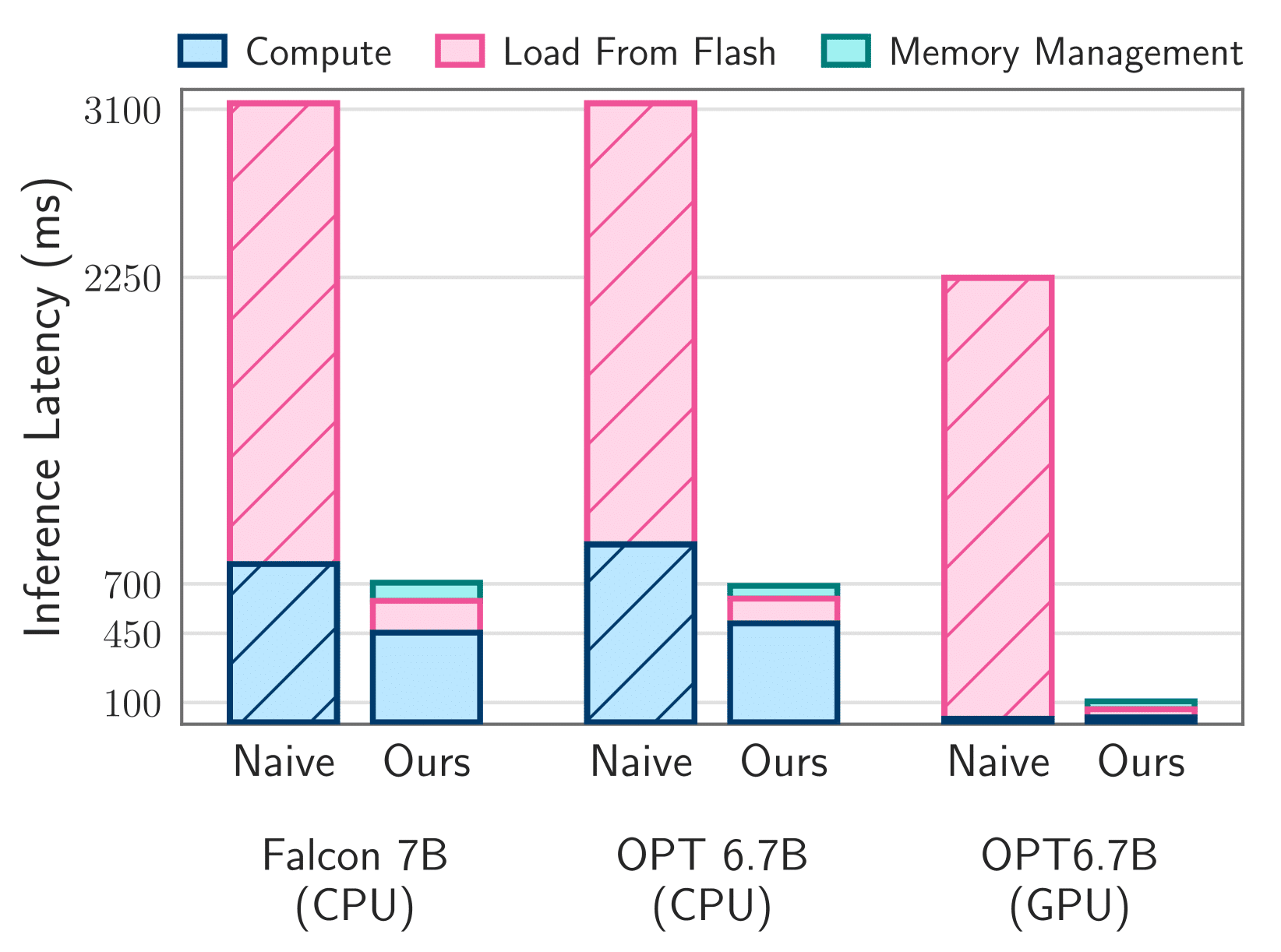
De acordo com a Apple, isso abre caminho para o uso de modelos duas vezes maiores do que a capacidade máxima da DRAM, com uma velocidade até 25x maior do que os métodos que envolvem a CPU10Central processing unit, ou unidade central de processamento. e a GPU11Graphics processing unit, ou unidade de processamento gráfico. como parte do processo de inferência12Inferência é basicamente o processo de, após o treinamento, um modelo fazer previsões ou tomar decisões com base em dados que ele ainda não viu..
Tá, mas o que isso tudo quer dizer?
Com o funcionamento proposto por esse estudo, a Apple teria o melhor de dois mundos a oferecer: um modelo grande, sem a restrição de tamanho da DRAM, porém rápido sem a restrição da velocidade da memória flash, em comparação à velocidade da DRAM.
Mais do que isso, a Apple vale-se de múltiplas técnicas e tecnologias já disponíveis do mercado, mas as costura de uma forma elegante, adicionando uma camada inteligente em que, basicamente, o sistema olha para si mesmo a todo momento, em busca de oferecer o próprio funcionamento da forma mais leve e eficiente possível.
Na prática, esse estudo abre caminho para que a Apple possa oferecer localmente um modelo com uma capacidade comparável à de uma IA baseada na web, o que por sinal, certamente será a próxima grande corrida do ouro no mercado das IAs generativas. De quebra, ele mostra que a Apple está atenta à nova guerra dos modelos de linguagem, que será travada não nos modelos de maior tamanho, mas sim em modelos menores, porém mais eficientes.
É óbvio que, para algumas tarefas, será necessário acessar a internet. A Siri, por exemplo, já funciona dessa forma. Mas ao adotar essa mesma premissa para algo como uma resposta ao ChatGPT, a Apple mostra que não está disposta a abrir mão dos seus princípios de privacidade nem mesmo quando se vê muito atrás da concorrência. E isso é excelente para todos nós.
Mais do que isso, ao propor uma nova tecnologia, mais eficiente e criativa do que as tecnologias em uso por todo o resto do mercado, a Apple finalmente começa a mostrar os frutos de todo o investimento que ela dizia há tempos que vinha fazendo nessa área, mas que até recentemente estava difícil de acreditar.
Notas de rodapé
- 1Large language models, ou grandes modelos de linguagem.
- 2Trocadilho com a tecnologia de memória NAND flash, responsável pela capacidade de armazenamento dos iPhones.
- 3Quantidade de “pesos” que os modelos utilizam para fazer previsões ou para gerar um texto.
- 4Segundo Hotz, o GPT-4 é um conjunto de 8 modelos com 220 bilhões de parâmetros cada.
- 5Video Random Access Memory, ou memória de acesso aleatório a vídeo.
- 6Termo para pedido, comando ou solicitação enviado a uma IA generativa.
- 7Small language models, ou modelos pequenos de linguagem.
- 8Dynamic random access memory, ou memória dinâmica de acesso aleatório.
- 9Obviamente a tecnologia é mais complicada do que dá para explicar em um parágrafo, mas o resumo é esse.
- 10Central processing unit, ou unidade central de processamento.
- 11Graphics processing unit, ou unidade de processamento gráfico.
- 12Inferência é basicamente o processo de, após o treinamento, um modelo fazer previsões ou tomar decisões com base em dados que ele ainda não viu.