


Já imaginou se alguém conseguisse descobrir o conteúdo da sua digitação apenas a partir do som das teclas sendo apertadas? Pesquisadores do Reino Unido desenvolveram um modelo de linguagem com precisão de até 95% que consegue fazer justamente isso, associando — de forma complexa — o som emitido pelo ato de digitar teclas específicas, de modo a identificar o que foi digitado apenas pelo barulho.
Conforme repercutido pelo BleepingComputer, Joshua Harrison, Ehsan Toreini e Maryam Mehrnezhad publicaram os resultados da pesquisa sobre o tema em um artigo. Eles conseguiram criar o modelo usando um MacBook Pro e o microfone de um iPhone 13 mini, posicionado a 17 centímetros do laptop.
O som emitido ao pressionar cada uma das 36 teclas do teclado do MacBook foi gravado 25 vezes cada, produzindo ondas sonoras e espectrogramas diferentes, como podemos ver abaixo. Com isso, pôde-se notar as diferenças no som gerado por cada tecla, de modo a ser possível identificá-las individualmente usando o som e, assim, treinar o algoritmo.
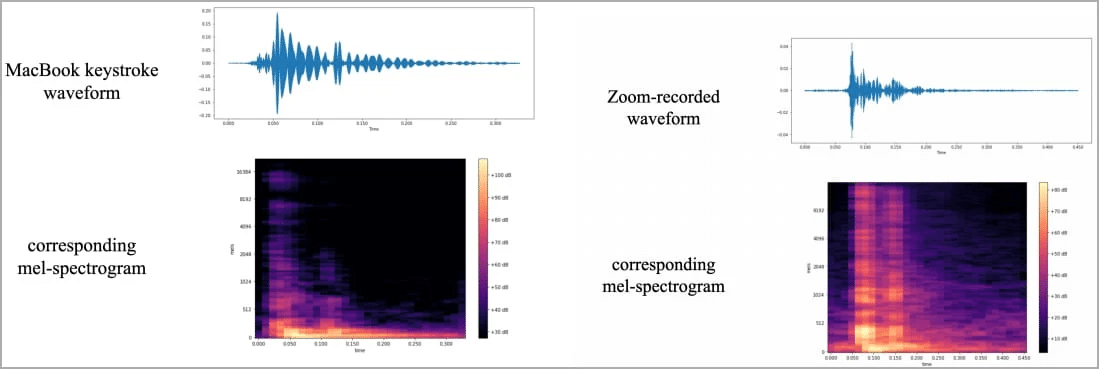
As imagens do espectrograma foram usadas para treinar um classificador de imagens chamado CoAtNet. O processo envolveu algum tempo de experimentação, taxa de aprendizado e parâmetros de separação das imagens para que a alta precisão fosse alcançada no algoritmo criado pelo grupo de pesquisadores.
Ao gravar o áudio diretamente do ambiente onde estava o MacBook, a precisão foi de 95%, enquanto, com o som de uma chamada do Zoom, o número caiu um pouco, mas ainda ficou no alto patamar de 93%, enquanto em ligações no Skype a proporção de acertos do modelo de linguagem foi de 91,7%.
Assim, estando em uma videochamada em grupo, por exemplo, alguém que quisesse descobrir o que você está digitando precisaria gravar a sua digitação e associar o som ao conteúdo escrito. Seria necessário calibrar o modelo ao teclado de cada pessoa para, então, realizar o procedimento descrito, explorando as diferenças entre os sons de cada tecla. Mesmo em teclados silenciosos a criação funciona, segundo os pesquisadores.
Vale lembrar que o risco desse tipo de algoritmo não apenas existe em relação a pessoas próximas ou que estejam em chamadas, mas também, por exemplo, com o uso combinado com malwares. Alguém poderia, assim, invadir o microfone do seu iPhone ou mesmo do Mac e, então, capturar o som da sua digitação em busca de senhas.
No artigo, os pesquisadores recomendaram como forma de mitigação do problema variar a maneira usada para digitar, em especial senhas e/ou informações sensíveis, ou usar senhas mais fortes. Também é possível usar softwares com filtros de áudio, que reproduzam ruído branco ou outro tipo de som para mascarar o da digitação.
A outra dica mais óbvia é, ao estar uma chamada, não digitar senhas ou silenciar o microfone quando for fazê-lo. Salvá-las em um gerenciador de senhas e usar recursos de preenchimento automático também é algo que neutraliza o uso de modelos de linguagem como o desenvolvido pelos pesquisadores. Não podemos esquecer, ainda, das Chaves-senha (Passkeys), que eliminam por completo a necessidade de digitação de senhas.
Quem diria que até mesmo digitar pode ser um risco, hein? 🤨