


Na semana passada, eu explorei o dilema moral de usar o excelente Arc Search para fazer pesquisas, sabendo que isso priva os sites da chance de exibirem os anúncios que os mantêm no ar.
Na coluna, tentei explorar como a própria existência do Arc Search é um sintoma de um problema muito mais amplo, sendo ele toda a estrutura que se formou em torno do mercado de buscas que, infelizmente, passou as duas últimas décadas divergindo de seu objetivo original: servir às necessidades do usuário.
Se, por um lado, o grande trunfo do Arc Search é acertar em cheio no emprego de LLMs 1Large language models, ou modelos de linguagem largos. para remover o atrito da experiência atual de busca, por outro lado, ele faz isso de uma maneira que só pode ser definida como pirataria, suprimindo tráfego aos sites de origem.
No artigo da semana passada, eu comparei o Arc Search ao Napster. Por coincidência, Chris Messina (também conhecido como o pai da hashtag) fez a mesma comparação na última quinta-feira.
Apesar da perigosa impressão de que esse é um problema que ainda está distante da realidade da web brasileira, essa questão foi amplamente discutida e explorada lá fora nesses últimos dias.
Por isso, para a coluna deste fim de semana, eu resolvi fazer um apanhado dos principais acontecimentos para quem quiser se aprofundar nesse importante assunto que, já antecipo, está longe de ter uma solução.
O caso Perplexity
No artigo do último sábado, eu citei a Perplexity como o exemplo do buscador com IA que melhor vem equilibrando o impasse entre entregar valor diretamente ao usuário, sem eliminar completamente da equação os sites que fornecem essas informações.

Por coincidência, os apresentadores do excelente podcast Hard Fork, do New York Times, entrevistaram Aravind Srinivas, CEO 2Chief executive officer, ou diretor executivo. da Perplexity. — e também por coincidência, o título do episódio menciona a possibilidade de a IA destruir a internet.
Na primeira parte da entrevista, os jornalistas Casey Newton e Kevin Roose 3Aquele que a IA da Microsoft tentou convencer a deixar a esposa para que eles pudessem fugir e se casar. exploram a oportunidade que ferramentas como a Perplexity têm de gerar impacto no mercado, já que o Google teria que canibalizar o próprio (e lucrativo) modelo atual para oferecer a mesma experiência.
Já na segunda parte, jornalistas e CEO discordam sobre o impacto negativo que ferramentas como a Perplexity podem ter no mercado de jornalismo. Enquanto Roose e Newton compartilham suas experiências de vivenciar as redações de veículos gigantes serem cada vez mais enxugadas ao redor do mundo, Srinivas reconhece que sua ferramenta tem responsabilidade sobre a situação, mas defende a estranha ideia de que talvez a saída seja desenvolver um novo modelo de negócio em que reconhecimento de marca seja mais monetizável.

No fim da contas, todos concordam que a tendência é que os veículos passem a responder a essas ameaças com uma intensificação da prática de paywalls 4Acesso a conteúdos somente para assinantes pagos., restrições de acesso e bloqueios de rastreadores 5Também conhecidos como crawlers. das IAs, assim como foi com o caso do New York Times — que por sinal está processando a OpenAI por uso não autorizado de suas matérias para treinar o ChatGPT —, Twitter, Reddit e tantos outros ao longo do último ano.
Toda a conversa é bastante franca, extremamente interessante e vale ouvir. De quebra, ela serve como um ótimo exemplo de que é possível ter pontos totalmente opostos sobre um assunto, sem apelar para a falta de educação. Fica a dica.
E falando em crawlers
No último artigo, eu comentei que a OpenAI havia lançado seu próprio rastreador web, o GPTBot, e o havia feito de modo que passaria a oferecer aos sites a escolha de terem ou não seus conteúdos indexados pelo ChatGPT.
Esta, para todos os efeitos, é atualmente a forma mais justa de lidar com o uso não autorizado de informações, ainda que, no caso da OpenAI, ela esteja fazendo isso apenas agora que todas as versões do GPT foram construídas com base em conteúdos utilizados sem autorização expressa dos seus autores. Mas esse assunto fica para outro dia.
Pois bem. Por coincidência, na última quinta-feira, o Instituto Reuters para o Estudo de Jornalismo, pertencente à Universidade de Oxford, publicou um levantamento bastante interessante que analisou os 15 sites de notícias mais acessados em 10 países, incluindo o Brasil, e se eles bloqueiam (ou não) os rastreadores de IA do Google e da OpenAI. Os resultados foram os seguintes (para Estados Unidos e Brasil):
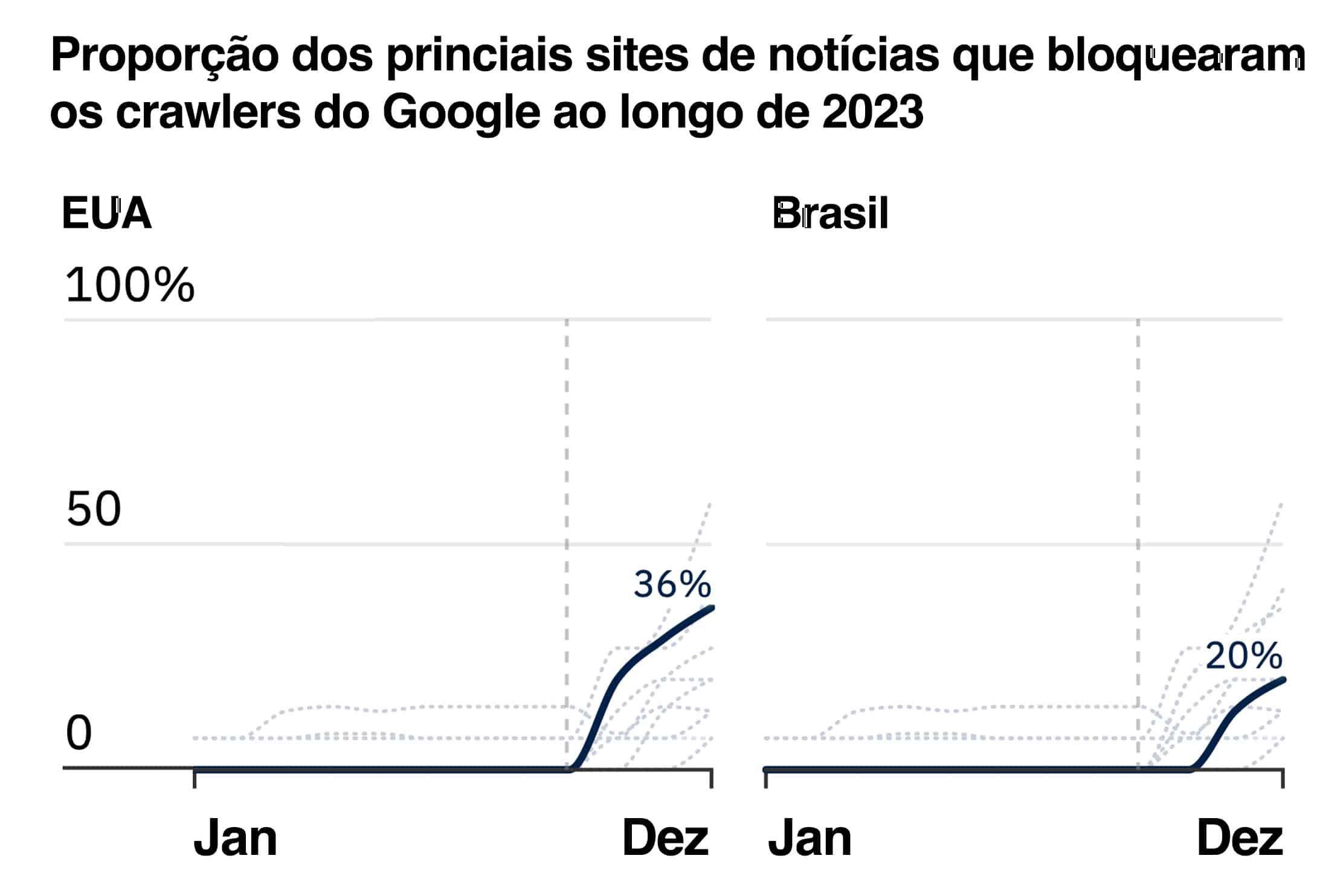
robots.txt dos 15 sites de notícias mais acessados em cada país (segundo o 2023 Reuters Institute Digital News Report) retirado a partir da Wayback Machine. Dados de dezembro de 2023 disponíveis para todos os sites, exceto o Washington Post nos EUA.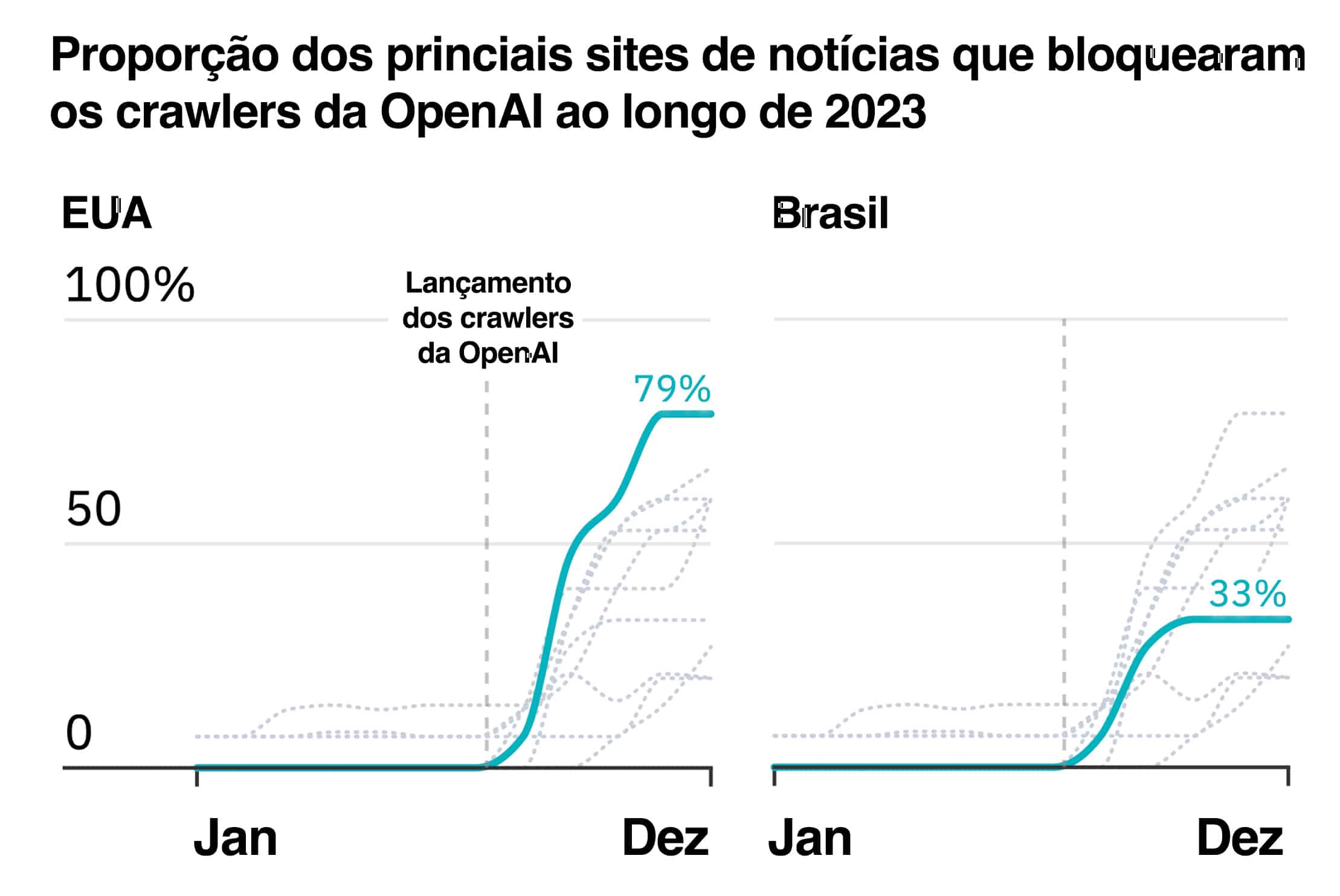
robots.txt dos 15 sites de notícias mais acessados em cada país (segundo o 2023 Reuters Institute Digital News Report) retirado a partir da Wayback Machine. Dados de dezembro de 2023 disponíveis para todos os sites, exceto o Washington Post nos EUA.O estudo completo, é claro, vale a leitura. Mas essencialmente, os resultados sugerem a comprovação da premissa que eu apresentei no início do texto de hoje: o mercado editorial americano parece estar bem mais preocupado em bloquear as IAs do que o resto do mundo, e os sites brasileiros ainda não parecem ter acordado para essa questão.
Outro achado interessante do estudo é o que diz que 97% dos sites que bloqueiam o rastreio da IA do Google, também bloqueiam o rastreio da IA da OpenAI, o que sugere que, quando os sites acordam para esse problema, eles passam a fazer de tudo para reconquistar o controle sobre seus próprios conteúdos.
A má notícia é que, como eu comentei na semana passada, bloquear rastreadores não é exatamente uma solução muito sustentável, já que isso depende de a empresa dona do rastreador oferecer a opção de fazer esse bloqueio. Esse, é claro, é o jeito mais respeitoso de lidar com a situação, mas sabemos que nem todas as empresas partilham do mesmo estoque de princípios.
Já a pergunta que fica é: se esse acabar se tornando o novo padrão de pesquisa da internet, será que valerá a pena para esses sites ficarem invisíveis para os motores de busca?
O problema do SEO
E falando em motores de busca, uma polêmica que precede a questão das IAs no mercado de busca é a questão do SEO 6Search engine optimization, ou otimização para mecanismos de busca. e a noção de que a otimização do conteúdo para uma boa indexação no Google tornou alguns confins da internet impossíveis de se navegar. Na semana passada, eu falei um pouco sobre isso e mencionei rapidamente a exacerbação desse problema com a dinâmica de links de afiliados.
Por coincidência, na última quarta-feira, os jornalistas Danny Ashton e Gisele Navarro publicaram uma exploração aprofundadíssima desse tema, em um post intitulado “Como o Google está matando sites independentes como o nosso”.
Ashton e Navarro exploram o motivo pelo qual, independentemente da busca, seja ela por dicas de presentes de Dia das Mães, seja por purificadores de ar, seja sobre saunas domésticas ou kits de coquetelaria, são sempre os mesmos sites que aparecem no topo, com conteúdos pasteurizados e raramente verdadeiramente úteis.
Além disso, os jornalistas exploram a fundo a tendência que se tornou comum no mercado editorial online dos últimos anos, em que firmas de investimento adquiriram parte de grupos de comunicação e têm transformado seus veículos em verdadeiras máquinas de rendimento de comissão por links de afiliados — para compensar, veja só, a queda na visualização de anúncios!
Como eu disse na semana passada, o SEO por si só não é a fonte do problema. Os profissionais de SEO não são a fonte do problema. E o próprio SEO ganhou um ar pejorativo que é parcialmente indevido. Mas apenas parcialmente. O SEO pode não ter causado o problema, porém mais e mais ele está longe de ser a solução.
E se a prática de fazer um artigo repleto de informações supérfluas para aumentar as chances de indexar bem no Google vem irritando os usuários, é natural que ferramentas como o Arc Search ou a Perplexity, que eliminam tudo isso e entregam apenas a informação que o usuário buscou, tenham chances maiores de fazer sucesso.
Resumo da ópera
Leitores mais atentos devem ter notado que eu mencionei a palavra “coincidência” em cinco oportunidades diferentes ao longo do texto.
Isso, é claro, não foi uma coincidência. E eu escolhi de propósito trazer apenas conteúdos que foram publicados após eu ter escrito a coluna da semana passada, para ilustrar como esse é um assunto que tem gerado discussões importantes e urgentes por todo o mercado, especialmente no exterior.
No fim das contas, o benefício oferecido pelos buscadores munidos com IA é inegável, e eu não tenho a menor dúvida de que esse será o novo padrão para buscas na web adotado em tempo recorde. Não falo especificamente sobre o Arc Search ou a Perplexity, mas sim sobre a interface e a experiência de busca e entrega direta da informação exata que o usuário buscou.
Por outro lado, o risco apresentado por esses buscadores é ainda maior do que o benefício, e isso é igualmente inegável.
É claro que, exageros à parte, eu não acredito que a web vá literalmente morrer por causa dessas IAs. O mercado editorial sobreviveu até hoje justamente por sua capacidade de se adaptar, e o mesmo deverá acontecer aqui. Resta saber quantos empregos isso irá custar — o que, para ser justo, é uma frase que pode ser dita sobre quaisquer outros trabalhos desempenhados pela humanidade quando o assunto é IA.
Notas de rodapé
- 1Large language models, ou modelos de linguagem largos.
- 2Chief executive officer, ou diretor executivo. da Perplexity.
- 3Aquele que a IA da Microsoft tentou convencer a deixar a esposa para que eles pudessem fugir e se casar.
- 4Acesso a conteúdos somente para assinantes pagos.
- 5Também conhecidos como crawlers.
- 6Search engine optimization, ou otimização para mecanismos de busca.